
Review of Open Research Problems in Rollup Design
2 November, 2023

📝 Introduction
📢 In this article, we aim to uncover the most critical unresolved issues in the design of rollup architectures. Addressing these challenges could fundamentally change the trajectory of specific technologies and the L2 solutions industry as a whole.
The crypto market, in its current phase of correction, is causing funds to flow from the majority of less promising sectors to a few truly vital ones for the survival of the industry. These sectors are less affected by market freezes, and experts in these fields continue to advance the technological potential of the sector.
One such sector is L2 scaling using rollups of various architectures. Over the past few years, we have observed a significant number of intriguing developments: updates in Optimism, Starknet, Polygon, and other major projects. The presence of such vibrant activity indicates that the industry is alive and thriving.
But what challenges remain unresolved today? Where can an ordinary engineer try their hand and seek fortune? How can one contribute to the development of L2 rollups? Let’s delve into our article! We will explore six primary research directions that are most relevant and crucial for the industry’s growth.
🧭 Rollup Key Principles
📢 To fully grasp the architectural challenges, it’s crucial first to understand the principles guiding the architecture of the most prevalent rollup types and the essence of these principles.
The architecture of rollups today follows three primary principles: Parallelism, Sequencing, and Commit to L1. Let’s delve into each one.
1. Parallelism
One of the fundamental principles underlying rollup architecture is parallelism. The essence of this principle lies in the simultaneous processing of multiple transactions, allowing a significant increase in network throughput. Instead of processing transactions sequentially, rollups employ parallelism to handle several transactions at once, substantially reducing wait times and speeding up transaction processing as a whole.
The primary tool for the practical implementation of parallelism is the integration of off-chain computation. The result of this computation is then incorporated into the rollup according to the correct sequence of incoming transactions for computation.
However, parallelism also comes with its challenges. Simultaneous transaction processing can lead to data conflicts or discrepancies. Hence, a key task in designing rollups is to establish mechanisms for the accurate and secure parallel execution of transactions.
2. Sequencing
The second principle logically stems from the first. If transactions are to be executed in parallel, it’s only logical that, immediately after their execution, we determine the sequence in which these transactions will affect the state transition. For this, rollups use various algorithms to ascertain the sequence of transactions. However, to date, there isn’t a single perfect algorithm; each has its advantages and disadvantages.
Unlike blockchains, rollups don’t use consensus to accomplish this task, which can compromise decentralization. However, this approach saves time by finalizing entire batches of transactions at once.
3. Commit to L1
Given that rollups do not utilize consensus mechanisms, they need to leverage the decentralization of primary blockchain networks. Therefore, the compactly packaged results of rollup operations are periodically recorded onto the main network via an on-chain component. This encapsulates the essence of our third principle.
To better understand the L1 commit process, refer to the diagram below:

Instead of committing each transaction to L1 individually, it is more efficient to commit a sequence of transactions at once, which can be represented by a single hash. The challenge, however, lies in encapsulating the results of processing multiple transactions into this one hash. Practically, this is achieved using a Merkle tree, which is quite convenient, as only the Merkle Root hash is required to confirm its validity.
It’s crucial to remember that the information contained in these on-chain commits should be accessible for verification and use by third parties. At the same time, all sensitive data within them must be adequately protected and only accessible to predefined entities.
From this feature, another requirement emerges: large rollups need cross-chain communication implementation, as it is the only method that ensures accurate access points to information about transactions processed in the rollup across all necessary networks.
It’s also worth noting that due to the periodic need for on-chain commits, the rollup indirectly depends on the throughput capacity of the main network. If the network experiences high traffic, the regularity of commitments may be compromised.
📢 Now, with an understanding of the principles upon which L2-Rollups are built, let’s discuss the challenges that researchers and architects still need to overcome to create an effective rollup.
🔍 Prob 1. Bridging off-chain and on-chain
📢 From the description of the three main principles, we understand that for a good rollup to work correctly, there needs to be a connecting component between the off-chain and on-chain parts. However, it is unclear what it entails. Let’s specify this problem!
By combining the first and third principles, we encounter the first problem. It lies in the need to implement methods of “bridging” off-chain and on-chain components of the rollup so that users have a way to deposit and withdraw assets from the rollup. Also, the rollup itself should be able to broadcast on-chain the results of the transaction processing in the off-chain module. In simple terms, a connecting link is needed that will allow the transfer of tokens, information, and requests from blockchain networks to the rollup and vice versa.
The theoretical aspect of this problem can be specified: a parallel transaction processing engine needs to be created that allows several participants of the network’s off-chain component to synchronously update the network state without violating the chronological sequence of incoming transactions.
This also means that wrapped versions of tokens need to be created for users, or native support needs to be introduced so that users can operate within the rollup ecosystem just as smoothly as in the main network.
Graphically, this problem can be illustrated as follows:

The practical aspect of this problem lies in the very high concentration of vulnerabilities in the architecture of such bridges. They are often hacked, and a genuinely secure method of implementing such an architecture has not yet been invented. Considering this aspect, we can expand the problem to the need to create a secure method of depositing and withdrawing assets from the rollup. Wrapped versions of tokens also need to be thoroughly checked for correct secure compatibility with their L1 versions.
🔍 Prob 2. EVM-equivalence for Rollups
📢 When considering the previous problem, we understood that a good rollup needs to have a tunnel between the off-chain and on-chain parts for transactions. But what about the execution of smart contract code on the rollup?
In order to build a highly scalable rollup, it must be capable of outsourcing the execution of smart contract code since this procedure often consumes a large portion of the block gas limit. Users should have the ability to deploy smart contracts and interact with them almost as they do in the main network. Furthermore, the outcome of contract logic execution should be consistent with that of the Ethereum Virtual Machine (EVM).
Practically speaking, this implies that a rollup (as one possibility) should have its own implementation of a virtual machine. However, real-world experience indicates that the primary challenge here is that the operation principles of the virtual machine often violate EVM-equivalence. This discrepancy is frequently evident in the gas cost of executing opcodes on the rollup VM, which may not always precisely mirror the gas cost of similar opcodes on the EVM. Various types of rollups exhibit this difference due to distinct engineering reasons, but the end result is consistent: smart contracts on the rollup VM might not behave in the same manner as they do on the EVM.
This poses a significant challenge, as it introduces unforeseen behavioral scenarios that might compromise either users or the rollup itself (for instance, through exploitation of the gas cost disparity between specific opcodes).
🔍 Prob 3. Corresponding data access
📢 Let’s assume the first two issues have been addressed, and we now have a rollup system that effectively transfers data between off-chain and on-chain components. This rollup system possesses the capability for both depositing and withdrawing funds and can execute the logic of any smart contracts and transactions. But how can we track all these operations? How can we trust it when we lack consensus and full transparency? This brings us to the third issue.
deally, data regarding processed and finalized transactions, as well as the algorithms of these operations, should be continuously updated and available for third-party verification. One might logically wonder, “Why not just replicate the blockchain’s process?” However, there are inherent challenges in doing so.
The primary concern here is that the need to send data both to L2 and L1 reduces the network’s maximum throughput. Essentially, our rollup must report its activities twice each time, which is understandably inefficient. Furthermore, there’s no guarantee that the L1 network’s throughput would support such double data dispatch.
Moreover, not all verification methods employed in blockchains can be seamlessly integrated into rollups.
One potential but somewhat cumbersome solution to this issue is the use of a proxy-layer (for example, Eigen Layer). This approach can reduce the technical barriers of throughput and alleviate network congestion. However, it is not entirely optimal due to several reasons: 1) We cannot assert its complete safety; 2) We cannot guarantee that the data will always be stored there; 3) We cannot ensure it won’t increase the cost of using the rollup. Therefore, a genuinely innovative solution to this problem could be a game-changer.
🔍 Prob 4. TX finalization gap
📢 To understand the essence of this problem, we need to firstly delve into the transaction finalization procedure in Ethereum.
All transactions are grouped by their execution time into slots, with each slot lasting 12 seconds. Every 32 slots are combined into an epoch. If everything proceeds normally, an epoch is updated every 6.4 minutes. This basic rule can be represented as:
⌛ 1 Epoch = 32 Slot = 32 * 12 sec = 6.4 min
When an epoch is considered finalized, all transactions processed during its period are also deemed finalized. For an epoch to be viewed as finalized, it must first achieve a supermajority in the validator voting. This is reached when ⅔ of the total balance of all active validators have voted in favor of including the transactions into the blockchain. This is referred to as epoch justification — an intermediate step before finalization. Once the subsequent two epochs have also been justified, our epoch is considered finalized.
This is a truly great mechanism that works fine. However, when introducing rollups into our puzzle, we inevitably face the unsettling fact that the entire finalization process takes no less than 16 minutes!
Meanwhile, the rollup operates parallel to the finalization procedure. This can lead to numerous issues! For instance, if it becomes clear on the rollup’s side that a transaction was processed with an error, the finalization at the L1 commit level will already have taken place, indicating a theoretical impossibility to rectify the identified issue. Additionally, this means there is an inherent impossibility to revert the commit in L1, significantly increasing the risks.
Below is a diagram illustrating this problem:
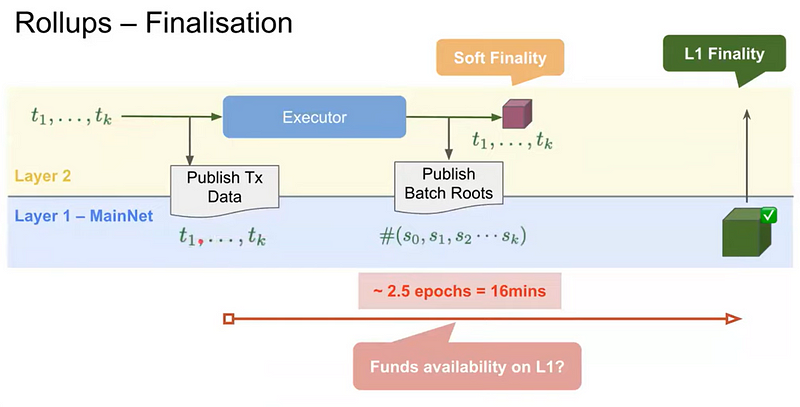
One theoretical approach to resolving this contradiction could be integrating the finalization mechanism directly into the rollup’s architecture. During an L1 commit, this would allow for the submission of already finalized transactions, which would then only undergo additional verification by the main network’s validators. However, there is no practical implementation of such a mechanism yet.
In any case, the overall objective can be formulated as follows: A mechanism is needed that will reduce the time gap between finalization on both L1 and L2, which will also allow users to freely manage their funds without having to wait for finalization.
🔍 Prob 5. BFT-reliable randomness on L2
📢 As many of you know, obtaining a reliable native source of randomness in a blockchain is nearly impossible. Oracles are commonly used to address this issue. But how do L2 rollups fare in this aspect? Let’s delve into it!
The challenge of ensuring reliable random selection in the context of L2 solutions is critically important for many aspects. Randomness should not only be unpredictable but also provably fair and non-reproducible. However, guaranteeing such quality randomness in a decentralized system, especially under L2 scaling conditions, is a complex task.
In blockchain, the synchronized operation of all network nodes is facilitated within the framework of Byzantine Fault Tolerance (BFT). BFT is a system property that allows the network to operate reliably and consistently even in the presence of nodes that act maliciously or incorrectly. In the context of randomness generation, this means that the system must be able to provide reliable randomness even if some validators attempt to manipulate the results or refuse to provide them.
From this perspective, the source of randomness for L2 should meet the following requirements:
- Decentralization: Randomness shouldn’t rely on a single node or a small group of nodes that could be compromised or attacked.
- Unpredictability: Outcomes should not be predictable until they have been officially published, ensuring no one can exploit knowledge of upcoming values.
- Fairness: Every participant in the network should have an equal chance of influencing or receiving a random number.
- Verifiability: Other nodes in the network should be able to verify the correctness of the random number generation.
- Efficiency: The system should be able to generate randomness without significant delays, ensuring the entire network’s smooth operation.
One of the challenges is selecting a mechanism that can guarantee randomness without the possibility of manipulation. Solutions might include the use of cryptographically secure pseudorandom functions, multi-signatures from various validators, or even hardware tools like quantum random number generators.
Another question is how to establish and maintain validator requirements to ensure BFT. This might encompass regular checks, reputation systems, penalties for manipulation attempts, and incentive systems to uphold a high level of service.
🔍Prob 6. Equilibrium in VM: fees and rewards
📢 Let’s assume we’ve resolved all previous issues and now have an almost perfect rollup. However, there’s still at least one crucial aspect left to address! How will we reward network participants? How will the system of checks and balances be structured? How will our rollup generate profit? Let’s delve into the core of the problem.
One significant issue is that after processing transactions on L2, we can never predict in advance how much it will cost to publish the results on L1. We can only calculate the amount of gas to be consumed, but its price varies based on network load.
Because of this, a situation might arise where the protocol pays for the publication of transactions out of its own pocket, leading to economic inefficiency. Conversely, the protocol might charge its users excessive fees for using the rollup, which is also not entirely efficient. Moreover, in the worst-case scenarios, such changes might jeopardize the profitability of strategies embedded in the rollup to generate profit.
From this, we can highlight the primary aspects of designing the economic model that require the most attention:
- Reward System: Defining an appropriate mechanism to reward network participants, including validators and other operators, for fulfilling their responsibilities.
- Uncertainty of Expenses: After processing transactions on L2, predicting the cost of publishing results on L1 becomes a challenging task. Despite the ability to calculate consumed gas, its price fluctuates due to varying network loads.
- Economic Risks: Due to the aforementioned uncertainty, situations might arise where the protocol covers expenses from its resources or, on the other hand, imposes excessive fees on users. Both scenarios can threaten the economic stability of the rollup.
This also underscores the need to develop something like a Rollup Gas Price Oracle, which would provide more accurate information about gas prices promptly or even slightly in advance.
Furthermore, developers should be provided with a clear specification of opcode operations in the virtual machine (so they can calculate gas economics), and rewards for validators and other network operators for each of their duties should be calculated. There are still many contentious points in this domain, and the research space remains open.
📝 Conclusion
📢 Now, we have a deep understanding of the fundamentally important issues in the architecture of L2 rollups. What conclusions can we draw?
- Most problems in the design of L2 rollups arise during the interaction of L2 components with L1: during commits, exchanging network state data, and the transmission of funds. This interaction is a fundamental bottleneck in the rollup architecture.
- To create an effective rollup, it should be designed in such a way that, once its operation cycle is fully completed, the reports on the results sent to the main network have already been verified, prepared for secondary use, and are directly accessible.
- It’s crucial to remember that when L2 interacts with L1, any asynchronicity can lead to undesirable consequences, and in extreme cases, to the inability to correct mistakes made. If the overall concept of the rollup allows, it’s better to eliminate asynchronicity entirely.
- In the competitive struggle among different architectures for rollups, there’s still room for new players who can firmly and confidently establish themselves in the market if they can address the discussed issues!
🗃️References
[1] — “Open Research Problems in Rollup Design” | Frank Cassez, Ethereum Engineering Group.
Contents
YOU MAY ALSO LIKE

Building Safe Anonymous Mail Module – Project journey with Aztec
Research
Discover Oxorio’s SAMM: Safe Anonymous Mail Module enabling email-based, zero-knowledge multisig approvals on Safe wallets via Aztec Noir.
30 June, 2025

What’s wrong with ERC20Permit?
Research
Explore our detailed analysis of the ERC20Permit vulnerability affecting top DeFi protocols. Learn about its impact, mitigation strategies, and how to secure your blockchain projects.
13 December, 2023

Securing Layer 2: Unique Security Concerns and Mitigation Strategies
Research
Explore the unique security challenges of Layer 2 blockchain solutions and learn about OXORIO's specialized strategies for mitigating risks in smart contracts and zk audits.
14 September, 2023
Have a question?

Stay Connected with OXORIO
We're here to help and guide you through any inquiries you might have about blockchain security and audits.
